
OpenInsight Dedicated Indexer Health
Overview
OpenInsight supports updating indexes directly on the server by running the index update process through the Windows Task Scheduler. If you have used the RTI_INDEXER_CONFIG window to create a scheduled task for updating indexes has the following ever happened to you?
- Someone disabled the indexer task and never re-enabled it.
- The user account password used by the scheduled task was changed or expired.
- The OEngineServer service was stopped and the indexes were not updating.
- Our application password changes and now the indexer can't login.
- The application was moved to a new server and no one remembered to setup the dedicated indexer.
Any one of the issues above can prevent the indexes from updating leaving the problem unnoticed for hours, days, or months.
This blog article walks through a method to add a watchdog timer to the index process. If the indexes stop updating the watchdog timer will expire and Nagios will trigger an alert so you can take action. While this article focuses on using Nagios for alert management the method should apply to other alert systems capable of receiving external notifications.
A familiarity with the dedicated indexer setup and a working Nagios server is recommended if you plan on following the article.
Indexer Watchdog Routine
After the index process completes the indexer watchdog routine will post a notification to Nagios to indicate the indexer process is still alive. The following function CS_INDEXER_WATCHDOG updates Nagios by HTTP request. Copy the function into your OI application and change the variables in the user defined comment section to match your Nagios server.
Function CS_INDEXER_WATCHDOG(void)
$Insert Logical
*
*Begin: User defined variables. Adjust to match your Nagios settings.
*
NagiosHost = 'augusta'
NagiosService = 'IndexFreshness'
APIUsername = 'augusta-98y965'
APIKey = '2398hasphpa34da293dj'
Url = 'https://nagios.example.com/cgi-bin/nagios3/cmd.cgi'
*
*End: User defined variables.
*
*Indicate if the program should break on error or continue running
*Set to TRUE$ during development for easier debugging
DebugOnError = false$
*Message returned by Nagios if host service accepted request
SuccessMsg = 'Your command request was successfully submitted to Nagios for processing.'
*Complete URL for Nagios
URLParms = 'cmd_typ=30&cmd_mod=2&host=':NagiosHost:'&service=':NagiosService:'&plugin_state=0&plugin_output=CheckOK&btnSubmit=Commit'
URLFull = URL : "?" : URLParms
Now = TimeDate()
LOG = 'Indexer finished execution at ' : Now
Gosub iwSetLog
Call CS_WriteEventlog(LOG, 'INFO')
oleObj = OleCreateInstance('WinHttp.WinHttpRequest.5.1')
oleResult = OleCallMethod(oleObj, "Open", 'GET', URLFull, 0)
iwStep = "Setting WinHTTP Open Parms"
iwStatus = OleStatus() ; Gosub iwCheckStatus
*Optional - Setup timeout methods for resolving DNS and server response
*http://msdn.microsoft.com/en-us/library/windows/desktop/aa384061(v=vs.85).aspx
iwStatus = OleCallMethod(oleObj, "SetTimeouts", 30000,15000,15000,15000) ;* All times in ms
iwStep = "Setting timeout values"
iwStatus = OleStatus() ; Gosub iwCheckStatus
*Specify the username and password to authenticate with the API as
oleResult = OleCallMethod(oleObj, "SetCredentials", APIUserName, APIKey, 0)
status = OleStatus()
iwStep = "Setting user and pass"
iwStatus = OleStatus() ; Gosub iwCheckStatus
*Execute the API request call
*Blocks until Timeout reached or response received
oleResult = OleCallMethod(oleObj, 'SEND')
iwStep = "Executing request"
iwStatus = OleStatus() ; Gosub iwCheckStatus
*Get the response value or error value
ResponseRAW = OleGetProperty(oleObj, 'ResponseText')
iwStep = "Reading ResponseText"
iwStatus = OleStatus() ; Gosub iwCheckStatus
If Index(ResponseRAW, SuccessMsg, 1) > 0 Then
LOG = 'Nagios confirmed update.'
End Else
LOG = 'Unable to verify Nagios accepted request.'
End
Gosub iwSetLog
Call CS_WriteEventlog(LOG, 'INFO')
Return
*
* End Main branch
*
*
* Branch to log errors into LOG
*
iwCheckStatus:
If iwStatus then
Log = iwStep : ' code: ': iwStatus
* If we want to break on error then
* reference the error variables for easy access
If DebugOnError EQ TRUE$ Then
LOG_ALL = iwLog
LOG_LAST = Log
debug
End
Gosub iwSetLog
End
Return ;*etiwagapomd
*
* Simple concatenation or logging function.
*
iwSetLog:
If Unassigned(iwLog) Then
iwLog = LOG
End Else
iwLog<-1> = LOG
End
Return ;*etiwagapomd
In addition to alerting Nagios the code will also post an event log message so you know the watchdog function is running. You can get the CS_WriteEventLog function here or simply comment out those lines.
The next step is to add this routine into the index update process.
Run the Watchdog Routine on Index Updates
Launch the the window RTI_INDEXER_CONFIG and open the configuration setup for your application. In the Post Index field choose CS_INDEXER_WATCHDOG as the post index process to run.
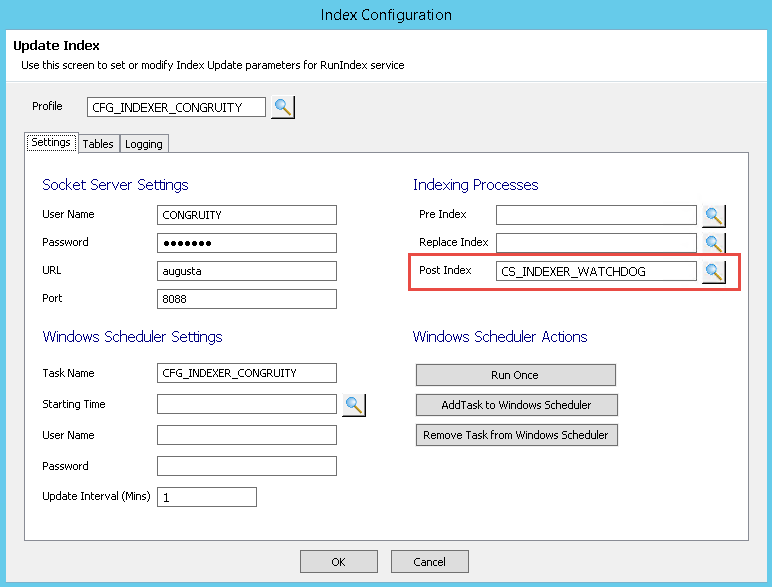
This will run the watchdog routine after the index process.
Save your changes but be certain not to re-add the scheduled task. The window has a nasty habit of overwriting the scheduled job after it's been configured with the correct user name and password.
Tip: After scheduling the task for the first time go back and remove the user name and password from the Windows Scheduler Settings section. This will prevent OpenInsight from being able to alter the scheduled job and accidentally erasing the saved credentials causing the scheduled task to fail.
The final step of the process is to configure Nagios to receive notifications from the watchdog function and send alerts when those notifications stop.
Configuring Nagios
To trigger an alert when the index fails to update Nagios will be configured with a new service that is checked passively. This means the index process (our watchdog function) must report its status on a regular basis. If it fails to check in after a predefined period of time Nagios will send an alert message. For information on how to configure a passive service check please refer to this blog article that walks through the process.
Here is an example Nagios configuration file which matches the OpenInsight code posted later in the article.
;
; Define contact, contactgroup, host, and service
;
define contact {
; Name corresponding to htpasswd username and password
contact_name augusta-98y965
alias Augusta
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,r
service_notification_commands notify-service-by-email
host_notification_commands notify-host-by-email
email [email protected]
}
define contactgroup {
contactgroup_name augusta-group
alias Augusta Contacts
; Add the contact directive member to contact group
members augusta-98y965
}
define host {
use generic-host
; Name of host passive check will reference when updating the service/host status
host_name augusta
alias augusta
; Assume host cannot be reached for active checks so the address can be arbitrary / not reachable
address augusta.example.com
; Assume host can.t be directly contacted and will report in status.
active_checks_enabled 0
; Accept passive checks for this host
passive_checks_enabled 1
; This associates which contacts (and htpasswd users) are allowed to update this host and service.
contact_groups augusta-group
}
define service{
use generic-service
; Associate this check with a host
host_name augusta
; Name of service passive check will reference when updating the status of this service.
service_description IndexFreshness
; When service becomes stale this check will be run to change the state to stale.
check_command stale_check
; A service is considered stale when freshness_threshold (in seconds)
; is reached. Set this to 1 to run the stale check as soon as the freshness threshold is reached.
check_interval 1
; Fail service after first active stale check
max_check_attempts 1
; Assume service state is OK
initial_state o
; Who should receive notifications for this service?
contact_groups admins
; Disable active checks (will still trigger active check after freshness threshold
active_checks_enabled 0
; Enable passive checks and ensure it is checked for freshness.
passive_checks_enabled 1
check_freshness 1
; Time since last passive check update before service is marked as stale
freshness_threshold 900 ; Result stale after 15 minutes (15 * 60)
flap_detection_enabled 0
check_interval 10
notification_period 24x7
; Only notify once when service is marked as stale
notification_interval 0
}
After applying the configuration restart Nagios and check to see if the IndexFreshness service appears. After a few minutes the status should turn to OK as shown in the image below.

You can verify the check is working by stopping the OEngineServer or disabling the Windows Scheduled Task. Within 15 minutes you should receive an alert indicating that the service is down and the status change to CRITICAL

Epilogue
Setting up failure notifications for the indexer service may seem like added headache but it will reap dividends when it allows you to proactively address problems before customers and clients start notifying you with problems that might not immediately appear to be related to stale indexes. Based on my experience it's only a matter of time before one or more of the common problems listed in the overview section will occur.
Questions, comments, ideas? Please contact me.
Author

Jared Bratu
Long time network sysadmin with proclivity to coding. Why do something twice when it can be scripted once? With a wide range of familiar technology skills Jared tries to apply the best aspects of each technology to projects leaving them better than they were before.
Leave a comment